[Previous Article] [Next Article]
Throughout 1996, forecasts for the tropical Pacific SST in the Niño 3 region have been presented in this Bulletin
using a neural network model with features such as an additional continuity term and a "clearning" term in the cost
function (Tang et al. 1994; Tangang et al. 1996). However, we are continually trying to improve the forecasts made by
our neural network models, because we believe that higher skills may be possible.
Recently, we have been dealing with an instability problem; namely, that the forecasts made by neural network
models using different training initialization and different data vary considerably, despite the fact that all have similar
overall skills. One of the causes of instability in the individual forecasts is that the neural network model has too many
weights, i.e., too many connections among neurons.
We thus applied different methods to prune the networks. One method we implemented is called Optimal Brain
Damage (OBD). In OBD, the importance of each weight is judged by the increase in the cost function (i.e., the model
error) when the weight is removed. The weight that causes least cost function increase is removed and the smaller
network is retrained. This procedure continues until only 3 weights are left. As the network is being pruned, its
performance is evaluated on both the training data and the test data, the latter of which are set aside from the training.
Usually, as the network is pruned, the error (cost function) on the training data increases, and the error on the test data
decreases to a minimum and then increases again.
To our surprise, the minimum in error on the test data turned out to occur when the neural network had been pruned
to an extremely simple one consisting of only one hidden neuron and 3 inputs. The connections to other inputs and other
neurons were all pruned away. The resulting network has only 4 weights in the following form:
x1(t + leadtime) = w4 tanh(w2 x1 + w2 x2 + w3 x3),
where w1, w2, w3 and w4 are the 4 weights whose values depend on the leadtime, and are listed listed in Table 1. The
predictors x1, x2, and x3 are the index of Niño 3.5 (5oN-5oS, 120-170oW; also called Niño 3.4) (obtained from CPC's
web site http://nic.fb4.noaa. gov/data/cddb) and the 2nd and the 3nd EOF coefficients of the FSU monthly wind stress
data (Goldenberg and O'Brien 1981). Before the EOF calculation, the wind data were first smoothed with one pass of
a 1-2-1 filter in the zonal and meridional directions and in time, and detrended and de-seasoned by subtracting from a
given month the average of the same calendar months of the previous four years. This pre-EOF processing is the same
as that used in Lamont's coupled model (Cane et al. 1986) and in Tang (1995).
We set the Niño 3.5 and wind stress data from 1961 to 1981 and from 1991 to 1996 as training data, and the data
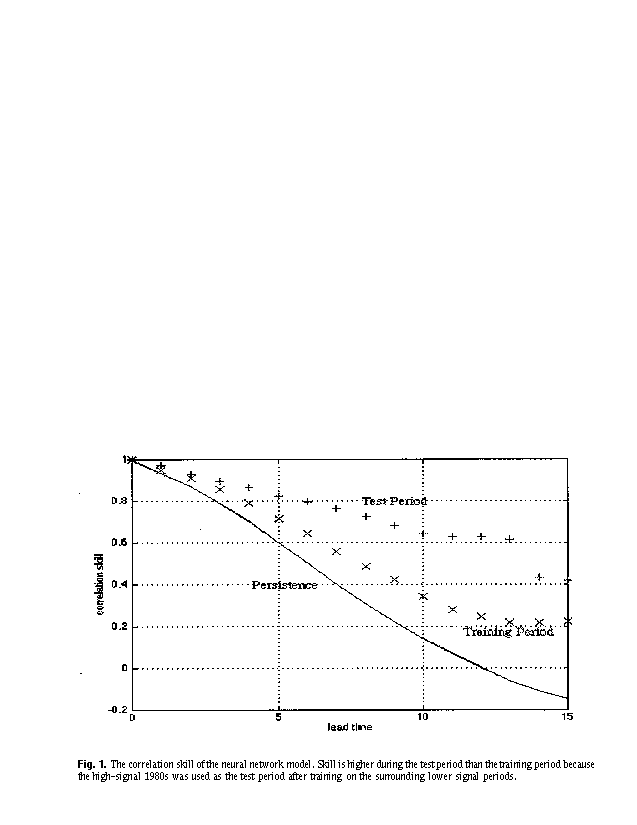
from 1982 to 1990 as test data. The reason of this division is that the test period consists of 2 warm events and 2 cold
events, so it is easy to see the strength of a trained model in forecasting an event. This active test period has a higher
signal/noise ratio than the training period, which resulted in the test period having higher skills than the training period
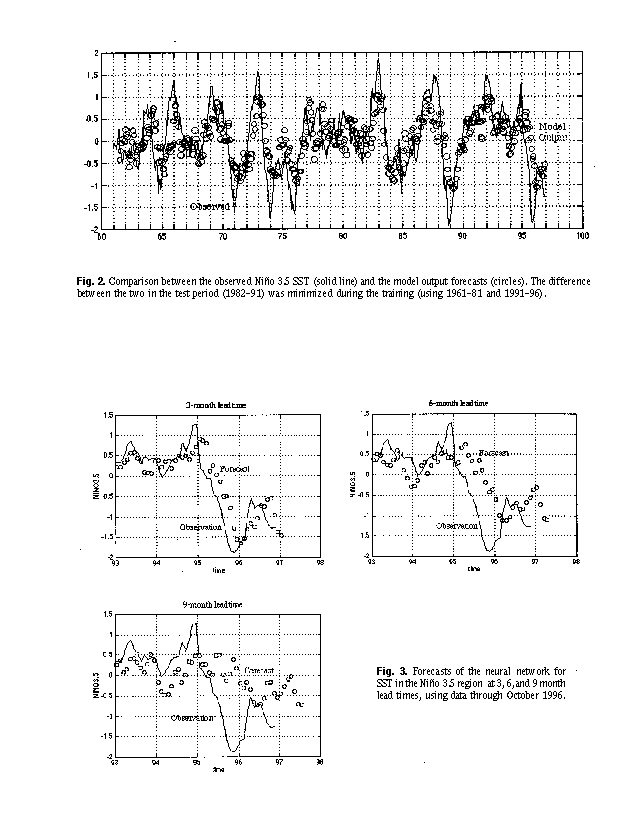
(Fig. 1). Figure 2 shows the comparison of the observed Niño 3.5 and the model output predictions at 6 months lead
time. The correlation skills are 0.64, 0.81, 0.69 for the training period, test period, and the two period combined,
respectively.
We compared this pruned neural network with a linear regression model consisting of the same input and output.
For the 3 month lead time, the two are almost identical. For the 6 month leadtime, the neural network is about 0.03
higher in correlation skill, while for the 9 month leadtime the skills are almost the same again. The small weights shown
in Table 1 reveal that the neural network does not go very strongly into a nonlinear regime; the tanh function is fairly
linear near the origin.
Fig. 3 shows the forecasts of lead times of 3, 6 and 9 months, using data through October 1996. The forecasts of
3 and 6 months lead show a continued cold condition in the Niño 3.5 region. This is consistent with our POP forecast
(issued monthly from our web site), which calls for continuation or intensification of the current cold condition for the
coming 2 seasons.
We have also developed a pruned neural network model for the COADS SLP data, which has higher skills than
the present model of FSU wind for longer lead times (Tangang et al. 1997). However, due to the lack of a consistent,
long, and timely updated SLP data set, we are unable to issue real time forecast with that model at the present time.
Table 1. The weights of the neural networks of different leadtimes. The weights are for the input and target data
which have been normalized to have a unit standard deviation.
lead time w1 w2 w3 w4
3 -0.2725 -0.0911 0.0908 -2.9908
6 -0.3162 -0.2558 0.2424 -1.6744
9 -0.1715 -0.4628 0.3741 -1.0595
Cane, M.A., S.E. Zebiak and S. Dolan, 1986: Experimental forecasts of El Nino. Nature, 321, 827-832.
Goldenberg, S.B., and J.J. O'Brien, 1981: Time and space variability of tropical Pacific wind stress. Mon. Wea.
Rev., 109, 1190-1207.
Tang, B., 1995: Periods of linear development of the ENSO cycle and POP forecast experiments. J. Climate, 8,
682-691.
Tang, B.,G. Flato and G. Holloway, 1994: A study of Arctic sea ice and sea level pressure using POP and neural
network methods. Atmos.-Ocean, 32, 507-529.
Tangang, F.T., W.W. Hsieh and B. Tang, 1997: Forecasting the equatorial Pacific see surface temperatures by
neural network models. Climate Dynamics, accepted.
Fig. 1. The correlation skill of the neural network model. Skill is higher during the test period than the training
period because the high-signal 1980s was used as the test period after training on the surrounding lower signal periods.
Fig. 2. Comparison between the observed Niño 3.5 SST (solid line) and the model output forecasts at 6 months
lead time (circles). The difference between the two in the test period (1982-91) was minimized during the training (using
1961-81 and 1991-96).
Fig. 3. Forecasts of the neural network for SST in the Niño 3.5 region at 3, 6, and 9 month lead times, using
data through October 1996.
{kind=link}
{kind=link}