[Previous Article] [Next Article]
Forecasts of Surface Temperature and Precipitation Anomalies over the U.S.
Using Screening Multiple Linear Regression
contributed by David Unger
Climate Prediction Center, NOAA, Camp Springs, Maryland
Screening multiple linear regression (SMLR) is used to predict seasonal temperature and precipitation amounts for locations over the mainland United States. Predictor data consist of northern hemisphere 700-mb heights, near global SSTs and station values of mean temperature and total precipitation amount from the 3-mo period prior to the initial time of December 1, 1997. Regression relationships were derived from data for the 1956-96 period. Forecasts were produced from single station equations for 59 stations approximately evenly distributed throughout the U.S.
All predictors and predictands were expressed as standardized anomalies relative to the
developmental data. Twenty-five candidate predictors, selected from gridpoint values in regions
of known importance for climate prediction, were offered for screening in the regression
development. A forward selection screening procedure was used for equation development. For
this forecast, the pool of candidate predictors for precipitation was limited to equatorial Pacific
SST's because of the overwhelming influence of ENSO.
A bi-directional retroactive real time validation technique was used to estimate forecast skill
(Unger 1996b). The predictor screening and equation length determination was also done in
retroactive real time mode, so that no knowledge of "future" forecast behavior was used in any
aspect of equation formulation. Equations varied from one to five terms. The verification is
based on the temporal correlation coefficient between forecast and observation on the 42
independent cases at each of the 59 stations.
The final forecasts are post-processed to obtain an estimate of the likelihood of the above, normal,
or below class being observed, as defined by the terciles of the distribution for each forecast
element and location. A forecast is assigned a class on the basis of the forecast distribution and
skill. An estimate of the increased likelihood of a given class is made to place the forecast in a
format similar to the operational long lead forecasts issued by the CPC (O'Lenic, 1994). Details
of the method used to assign probabilities to these forecasts can be found in the March 1997 issue
of this bulletin. (Unger, 1997)
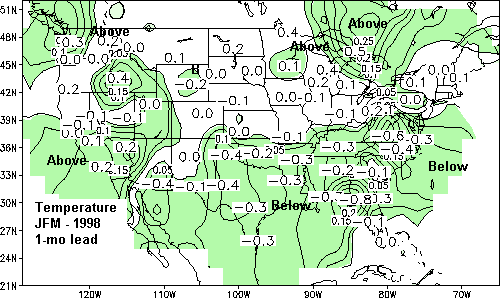
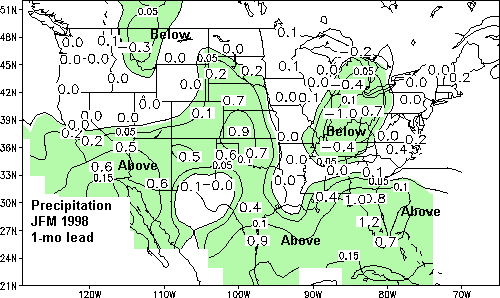
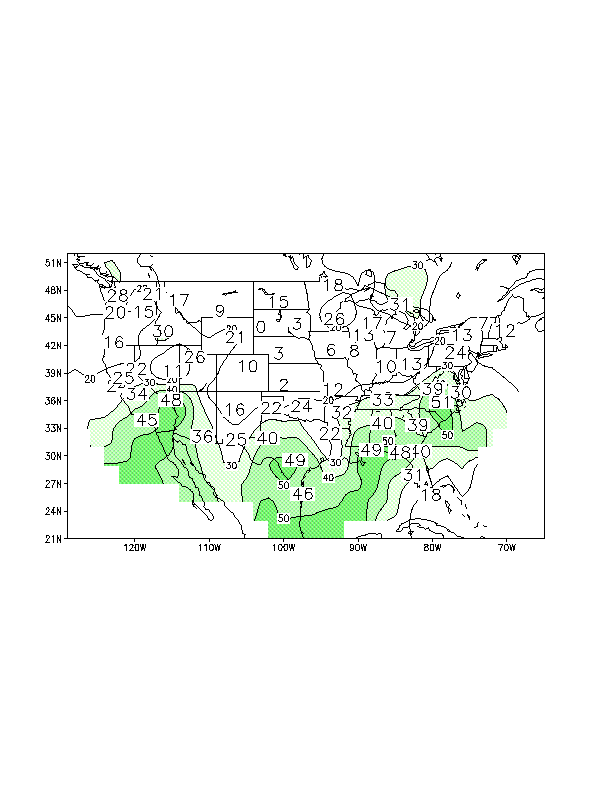
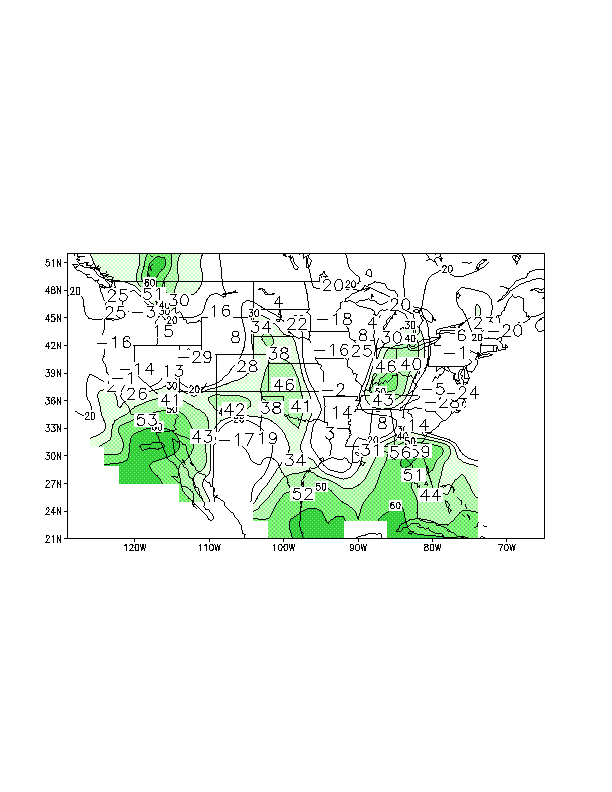
The forecasts for JFM 1998 are shown in Figs. 1 and 3 with the corresponding skill estimates for
each station shown in Figs. 2 and 4. Shading indicates areas of sufficient skill to assign a tercile
category to the forecast. Contours within the shaded areas on the forecast maps indicate
probability anomalies for the category at 5 percent increments. The numbers plotted in Figs. 1
and 3 indicate station values of the original regression forecasts, damped according to the
forecast-observation correlation on independent data to minimize the squared error.
Regression forecasts for JFM 1998 (Fig. 1) show above normal temperatures over southern
California, Washington State, the Great Lakes, and in the inter-mountainous West. Below normal
temperatures are predicted for the south-central and southeastern U.S.
Precipitation forecasts for JFM 1998 (Fig. 3) show below median amounts for western Montana
and the Ohio River Valley. Above median amounts are predicted for much of the southern
portion of the U.S. and in the high plains region from South Dakota southward.
REFERENCES
O'Lenic, E., 1994: A new paradigm for production and dissemination of the NWS's long lead-time
seasonal climate outlooks. Proceedings of the Nineteenth Annual Climate Diagnostics Workshop.
College Park, Maryland, November 14-18, 1994, 408-411.
Unger, D. A., 1996a: Long lead climate prediction using screening multiple linear regression.
Proceedings of the Twentieth Annual Climate Diagnostics Workshop. Seattle, Washington,
October 23-27, 1995, 425-428.
Unger, D. A., 1996b: Skill assessment strategies for screening regression predictions based on a
small sample size. Preprints, Thirteenth Conference on Probability and Statistics in the
Atmospheric Sciences. San Francisco, CA., February 21-23, 1996, 260-267.
Unger, D. A., 1997: Conversion of Long Lead Climate Predictions from Continuous to
Probabilistic Form. Proceedings of the Twenty-first Annual Climate Diagnostics and Prediction
Workshop. Huntsville, Alabama October 28-November 1, 1996, 44-47.
Figure 1. A 1-mo lead screening regression-based temperature forecast for JFM 1998. Contours
are estimated probability anomalies of the specified tercile. Shaded areas delineate the area of
sufficient skill to depart from climatology by at least 3 percent. Plotted numbers are station
values of the standardized anomaly.
Figure 2. Distribution of skill for the 1-mo lead regression forecast for JFM 1998 temperatures.
Both the plotted values and the contours are the correlation (x100) between forecast and
observation for the 1955-1996 period.
Figure 3. Same as Fig. 1 except for precipitation forecasts.
Figure 4. Same as Fig. 2 except for precipitation skill.
{kind=link}
{kind=link}
{kind=link}
{kind=link}